

Sorry I [haven’t replied to your email / couldn’t make your event / have been ignoring your texts]. I’ve been vibecoding.
Like everyone else, I’ve gotten addicted to Claude Code. (It happens to be the tool I picked up first, but I’ve heard that OpenAI Codex, Cursor, Replit, etc. are all also quite good.) I’m exactly in the most susceptible demographic for it: a former software engineer, product manager, engineering manager, and tech startup co-founder who through circumstance has not had time to code, even for fun, in several years. In my case, it’s because I became a writer and nonprofit leader, and also a dad; but the same thing is happening to tech CEOs and others. All of us are intoxicated by the amazing newfound productivity of AI coding agents, which are now unlocking years-old backlogs of product ideas, bug fixes, and pet projects.
Let’s step back and recap how we got here. The first GPTs were research prototypes, not yet products. GPT-2, launched in February 2019, struggled to produce coherent, logical text (see examples here). Progress came mainly came from scaling up training runs and model size, from hundreds of millions of parameters for GPT-1 to now hundreds of billions or maybe trillions of parameters in the most capable models.
What this created was not a full artificial intelligence but artificial intuition. It could “answer off the top of its head,” it had a superhuman recall for facts, and it could blurt out not just sentences but entire essays. But it was still blurting out all its answers, with no ability to “think” before “speaking,” check its work, or follow an explicit procedure—not even, say, long addition.
By 2022, this had become such a limitation that it was possible to dramatically improve GPT-3’s performance on mathematical reasoning problems simply by concluding the prompt with “Let’s think step-by-step,” which encouraged models to work through the problem explicitly rather than trying to blurt out an answer. Soon this approach was built into the product, in a new class of “reasoning” models, such as OpenAI’s o1, that were given the ability to “think”—that is, to talk to themselves in a scratchpad—before producing a response.
In parallel, the models’ coding ability was growing. At first, LLMs were built into the IDE (“integrated development environment,” kind of a text editor on steroids that software engineers use to write code), and they took the form of autocomplete: the developer would start to type code, and the LLM would complete it. This made it faster to write many routine functions. Later AI-assisted IDEs could write or modify an entire snippet of code from an English description, or answer questions about the code, or discuss it with the engineer. Then the AI got good enough that you could just tell it what to do next, and the output was reliable enough that you didn’t even really need to review it carefully, at least for low-stakes hobby projects—what Andrej Karpathy dubbed “vibe coding.”
The other thing that developed in parallel was the models’ ability to pursue goals, as autonomous agents. At the core, of course, an LLM is simply a statistical model of text that predicts the next token; since any predictor can be made into a generator, this allows it to take a prompt and generate a response. A text generator is not an agent and does not pursue goals—but it was clear from the beginning how an agent might be built from them. Just provide it with a small scratchpad and a few tools it can invoke. Then tell it a goal, and run it in a loop: given the goal, make a plan to achieve it, execute that plan, then check if the goal was achieved; if not, replan and begin again; continue until you succeed.
Early experiments with this (such as AutoGPT, March 2023) were toys: they didn’t have enough intelligence, large enough context windows, or coherence across long enough timescales to accomplish anything of note. But all of this has been improving. The models have been been trained in better tool use, and have been given tools including web search, file access, and code execution; they’ve been given larger context windows, now up to 1 million tokens; and they have steadily been increasing in long-term coherence. Indeed, the length of task (in human-equivalent minutes) that a model can perform has become a key metric of AI progress:
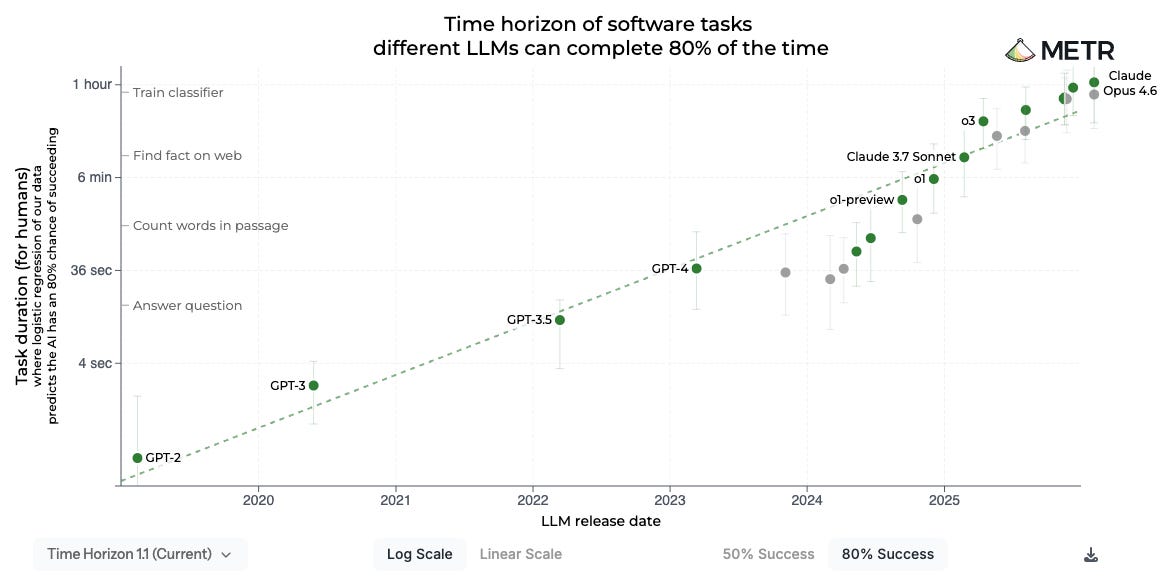
Put all of this together—the “reasoning” mode, better coding, and greater agency—and by late last year we had crossed a tipping point: Some software developers stopped writing code themselves, and started letting agents write 100% of it. The job of the engineer became planning, identification of tasks, directing the AI to specific goals, possibly giving high-level technical direction, testing the output, and (perhaps, depending on how fastidious you are) reviewing the code that is generated. That is, software engineers are becoming more like product managers, engineering managers, and tech leads—as I predicted, humanity stepping up into management. Andrej Karpathy says the term “vibecoding” no longer does justice to what’s possible: it’s now “agentic engineering.”
I felt this shift personally. In early 2025, I was able to use Cursor to write a Python script to analyze CSVs of my workout logs and make some charts of my exercise performance. AI sped me up a lot, especially since I wasn’t familiar with libraries for processing and charting data (like pandas or Matplotlib). The LLM saved me a lot of time reading docs and tinkering; I could focus on the core task I was trying to accomplish. But I was still directing the coding at a detailed level. By early 2026, I was able to act as the product manager, not the developer: to ask Claude Code to simply implement my ideas. Already I’ve built a personal todo app with web and mobile UIs that works offline; a site uptime monitor for the Roots of Progress’s various websites; and an iPad game for my preschool-age daughter to learn two-digit addition.
Part of why this is such a huge unlock is that writing code demands a level of focus I simply don’t have these days. It requires multi-hour blocks of uninterrupted time where you can get your head deep into the problem and the code. Between my day job, my parenting duties, and the need in my 40s to get regular sleep and exercise, that kind of hobby just isn’t possible. But directing coding agents is a different thing altogether: it can be done on “manager schedule” rather than “maker schedule.” Garry Tan describes it using the metaphor that it’s as if he used to be a competitive runner (i.e., engineer) who got a knee injury (went into management). But now he has a knee replacement (coding agents)—and it’s a bionic knee, better than before. Shopify CEO Tobi Lutke has been coding up a storm, and even used Claude to create a viewer for his MRI data.
Out of the box, coding agents lack training and professional maturity. They’re like junior engineers, very smart but fresh out of college and operating like cowboys. When I started my first app, I suggested to Claude Code that I write a product spec, from which it could create a tech design that I would review, before proceeding to implementation. Oh, that sounds like too much process, it told me, why don’t you just tell me your idea and I’ll whip it up? OK fine, we’ll try it your way, I thought. It worked well at first, but then as these things always do, the app started to get buggy. I soon realized Claude wasn’t even writing automated tests (a very basic practice). Over time, I’ve leveled up my Claudes with best practices from the software world: automated regression tests; “test-driven development,” in which you write the tests before the code to make sure the tests actually catch bugs; doing each change on a separate branch which gets reviewed and tested before it is merged into the main line; creating separate testing environments so as not to interfere with real production data; etc.
At first, I thought I would do this by writing one big practices document and having each agent review that at the beginning of each session. But it turns out there’s a better way: “skills”, which are brief documents describing one procedure or technique. These can range from how to use a particular app framework to general best practices the agent should always follow. Agents like Claude Code are able to ingest a large volume of skills, holding only brief, high-level descriptions of each in their context window, and searching for skills when they might be relevant, so the full text can be brought into context only when needed. People are publishing their skills, and there are entire skills marketplaces. I started with a set of basic engineering practices from Jesse Vincent, and then have been writing my own as I notice things Claude could do better. Well, of course, I haven’t been writing them: I’ve been having Claude draft them, and then I’ve been reviewing and commenting on them. The experience is much like having a highly trainable employee who takes feedback and earnestly attempts to improve.
When I started, I would delegate a task and then do something else for a little while until the agent was finished. But once I had 3–4 agents working in parallel across two or more projects, I found that I was fully occupied just reviewing their work and prioritizing next steps; it took all my focus just to keep them busy. What this means is that I’m now able to make progress on software development at the speed of my own review and decision-making—which is amazing.

Stepping back, I think a lot of progress since ~GPT-3 has been in taking the core intuitive faculty provided by statistical language models and adding layers of self-monitoring and self-control, such as reasoning and skills. I find it remarkable how much LLMs are aided by some of the same practices that help humans be more effective: working problems out on a scratchpad, planning before executing, and all of the structure and practices that human engineers, designers, and product managers put in place around software development. Elsewhere, Wilson Lin at Cursor reports on an experiment with getting a large team of agents to implement a web browser from scratch, a large undertaking (although one for which there is already a comprehensive set of formal specifications and acceptance criteria). Just getting a bunch of agents to work off of one big shared task list was too chaotic. What worked was having certain agents dedicated to planning—assessing status and figuring out what was needed next to reach the goal—while other agents acted as implementers, picking tasks off the plan and getting them done without worrying too much about the big picture. Again, systems of self-monitoring and self-control.
The biggest limitation on these systems right now, it seems to me, is memory. They start each session like Leonard Shelby from Memento, with no short-term memories, needing to review all their notes to get context. This is a very limited form of learning. An LLM can’t develop intuition or taste post-training—which, as Dwarkesh pointed out, means it can’t learn on the job the way a human does. Claude’s memory file generated from our chats is about 400 words, ChatGPT’s is not much over 100; a human assistant who had talked to me as much as they have would have a much deeper understanding of me. No doubt this limitation, too, will be removed sooner or later; I agree with Ethan Mollick when he suggests that this will be transformative.
In any case, to produce an acceptable app right now, even a simple one, requires me to act as the product manager and the tech lead. I’m giving direction about what to do; I’m training the agents in best practices and watching to make sure they follow them; I’m even exercising high-level oversight about technical decisions and making technical suggestions. I’m only capable of this because I spent almost twenty years in the tech world, doing these roles professionally across several teams and projects. I can only imagine that users without that experience would have a hard time creating an app of any size and complexity without getting bogged down in confusing product design, annoying bugs, and slow performance. But on the current trajectory, we’re only a year or so away from whole teams of agents that work together like a complete dev shop. A client could come to the process with only a vague, high-level idea of what they need. A product manager agent would interview them to discover requirements. The PM would write a product spec, and a design agent would create UI mockups, both of which the user could review and comment on. Once the spec and design were approved, an engineering agent would produce a tech design; perhaps a second agent with fresh context would review and revise it. A planner agent would turn it into a task list, and a team of implementer agents would execute the coding tasks in parallel, with reviewer agents examining the code for bugs, weaknesses, and best practices. The app would periodically be presented back to the client for user testing and feedback, for as many rounds of iteration as needed to leave the client fully satisfied. On the whole, it would be much like the process performed by humans, but it would take orders of magnitude less money and time.
This is going to change the nature of software. Already I notice a shift in my product thinking: instead of designing an app for a market, I can design it for myself. I don’t have to worry about any other user’s requirements, about competition and gaps, about user onboarding, or about pricing and payment. It simplifies a lot, compared to being a tech founder. I don’t think all software will be bespoke in the future, not even nearly all of it, but there will be a lot more custom software than before.
And it is not hard at all to envision how this will play out in other industries whose work essentially consists of talking to people and producing documents: law, accounting, graphic design, business consulting. Virtual service shops, doing in hours what used to take weeks, for hundreds of dollars instead of tens of thousands.
It is now impossible not to see that this is going to change the world, indeed that the change has already begun and is underway in earnest.
For me, the big shift has been qualitative, not quantitative. I find myself thinking of making things that I would never have made before. Not because they were impossible, but because the result didn't justify the effort. I'm not just making more things, I'm making _different_ things.
Very similar experience here - thanks for sharing. It's been remarkable to see what I can cook up in a day that I wouldn't otherwise amidst the chaos of doing a start-up. There's a curious side effect that's been happening as well, which is that as I transition some general-purpose multi-user SaaS applications to custom-coded and self-hosted variants, I am seeing a remarkable increase in performance. One workflow that I transitioned off of Notion to something that works exactly the way I wanted not only increased the functionality but saw a (literal!) 1000x performance speed-up of queries.
It made me wonder: how much of the overhead of the modern SaaS ecosystem has to do with the fact that the systems have to manage, route, segment, performance optimize millions of users? What would a world look like if each person had a custom server for their applications, and the only routing/data segmentation that had to happen is the DNS lookup and authentication to get your phone or desktop to talk to your server?
Maybe there's a version of the future where this is the norm, especially as these agents get to the point where an every day consumer can say "I want an app that does X" and can iteratively tell their agent whatever tiny little feature modification they want to make, and it makes the changes live on their own custom server and application stack. I know Base 44 and some others are advertising themselves as such but I don't think it's quite what I'm imagining, because ultimately these are still SaaS companies that have to deal with the complexity of many users on their servers and have guardrails about what is allowed, so they will always be playing catch-up with technology as it comes out.